The brightest comet of the year will reach perihelion on Monday, January 13. Here’s what to know about Comet ATLAS C/2025 G3.

At CES 2025, Nvidia CEO Jensen Huang kicks off CES, the world’s largest consumer electronics show, with a new RTX gaming chip, updates on its AI chip Grace Blackwell and its future plans to dig deeper into robotics and autonomous cars.
Never miss a deal again! See CNET’s browser extension 👉 https://bit.ly/3lO7sOU
Check out CNET’s Amazon Storefront: https://www.amazon.com/shop/cnet?tag=lifeboatfound-20.
Follow us on TikTok: https://www.tiktok.com/@cnetdotcom.
Follow us on Instagram: https://www.instagram.com/cnet/
Follow us on X: https://www.x.com/cnet.
Like us on Facebook: https://www.facebook.com/cnet.
CNET’s AI Atlas: https://www.cnet.com/ai-atlas/
Visit CNET.com: https://www.cnet.com/
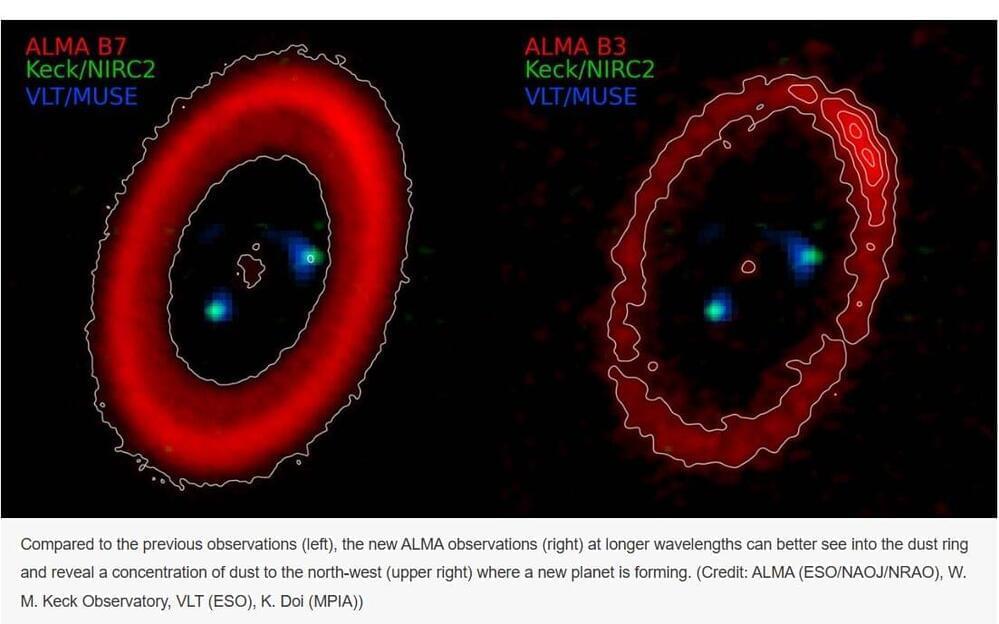
New radio astronomy observations of a planetary system in the process of forming show that once the first planets form close to the central star, these planets can help shepherd the material to form new planets farther out. In this way each planet helps to form the next, like a line of falling dominos each triggering the next in turn.
To date over 5,000 planetary systems have been identified. More than 1,000 of those systems have been confirmed to host multiple planets. Planets form in clouds of gas and dust known as protoplanetary disks around young stars. But the formation process of multi-planet systems, like our own Solar System, is still poorly understood.
The best example object to study multi-planet system formation is a young star known as PDS 70, located 367 light years away in the direction of the constellation Centaurus. This is the only celestial object where already-formed planets have been confirmed within a protoplanetary disk by optical and infrared observations (First Confirmed Image of Newborn Planet Caught with ESO’s VLT (ESO) ). Previous radio wave observations with the Atacama Large Millimeter/submillimeter Array (ALMA) revealed a ring of dust grains outside the orbits of the two known planets. But those observations could not see into the ring to observe the details.

Case Western Reserve University researcher advances zinc-sulfur battery technology. Rechargeable lithium-ion batteries power everything from electric vehicles to wearable devices. But new research from Case Western Reserve University suggests that a more sustainable and cost-effective alternative may lie in zinc-based batteries.
In a study published recently in Angewandte Chemie, researchers announced a significant step toward creating high-performance, low-cost zinc-sulfur batteries.
“This research marks a major step forward in the development of safer and more sustainable energy storage solutions,” said Chase Cao, a principal investigator and assistant professor of mechanical and aerospace engineering at Case School of Engineering. “Aqueous zinc-sulfur batteries offer the potential to power a wide range of applications — from renewable energy systems to portable electronics — with reduced environmental impact and reliance on scarce materials.”


Neuromodulators in the brain act globally at many forms of synaptic plasticity, represented as metaplasticity, which is rarely considered by existing spiking (SNNs) and nonspiking artificial neural networks (ANNs). Here, we report an efficient brain-inspired computing algorithm for SNNs and ANNs, referred to here as neuromodulation-assisted credit assignment (NACA), which uses expectation signals to induce defined levels of neuromodulators to selective synapses, whereby the long-term synaptic potentiation and depression are modified in a nonlinear manner depending on the neuromodulator level. The NACA algorithm achieved high recognition accuracy with substantially reduced computational cost in learning spatial and temporal classification tasks. Notably, NACA was also verified as efficient for learning five different class continuous learning tasks with varying degrees of complexity, exhibiting a markedly mitigated catastrophic forgetting at low computational cost. Mapping synaptic weight changes showed that these benefits could be explained by the sparse and targeted synaptic modifications attributed to expectation-based global neuromodulation.
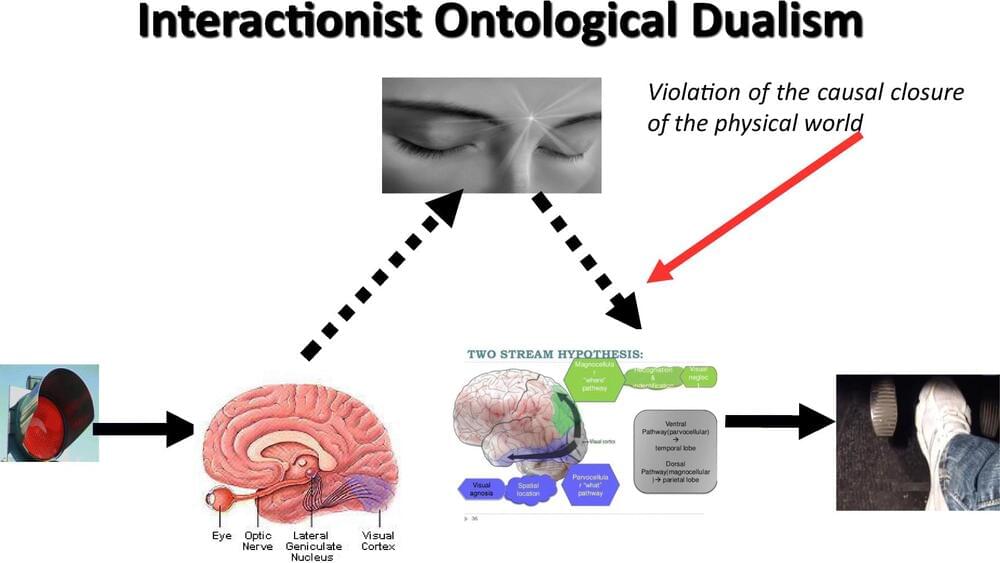
Using an analysis of a voluntary action caused by a visual perception, I suggest that the three fundamental characteristics of this perception (being conscious, self-conscious, and provided with a content) are neurologically implemented by three distinct higher order properties of brain dynamics. This hypothesis allows me to sketch out a physicalist naturalist solution to the mind-body problem. According to this solution, primary phenomenal consciousness is neither a non-physical substance, nor a non-physical property but simply the “format” that the brain gives to a part of its dynamics in order to obtain a fine tuning with its environment when the body acts on it.

The relationship between brain and computer is a perennial theme in theoretical neuroscience, but it has received relatively little attention in the philosophy of neuroscience. This paper argues that much of the popularity of the brain-computer comparison (e.g. circuit models of neurons and brain areas since McCulloch and Pitts, Bull Math Biophys 5: 115–33, 1943) can be explained by their utility as ways of simplifying the brain. More specifically, by justifying a sharp distinction between aspects of neural anatomy and physiology that serve information-processing, and those that are ‘mere metabolic support,’ the computational framework provides a means of abstracting away from the complexities of cellular neurobiology, as those details come to be classified as irrelevant to the (computational) functions of the system.

{kind=link}