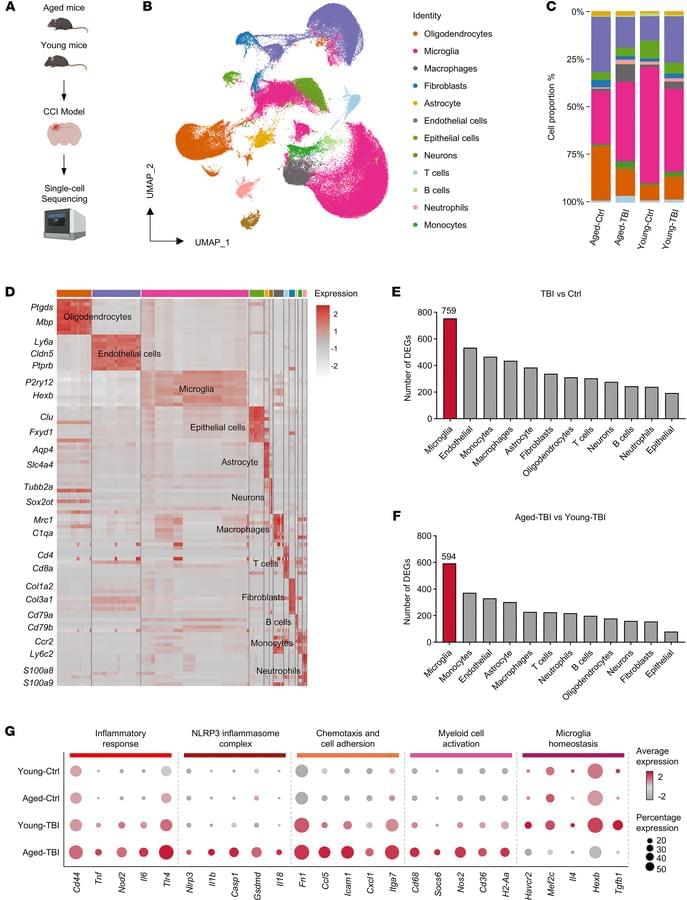
Matt White is the AI CTO at the Linux Foundation. He just got back from visiting DeepSeek, Moonshot, Zhipu, Qwen, and Minimax in China.
In this episode:
What he saw inside China’s top AI labs that the West doesn’t know.
4 Chinese breakthroughs US labs are quietly building on.
Why export controls backfired and forced China to innovate faster.
150 humanoid robot startups, China builds the body, America builds the brain.
The biggest mistake enterprises make with AI
Where he’d put $1M in AI right now.
Chapters.
00:00 — Intro.
00:54 — Inside China’s AI Labs.
09:43 — DeepSeek’s Culture & the Distillation Debate.
17:03 — Open Source Models vs Commercial APIs.
27:28 — How Startups Should Choose Their AI Stack.
41:17 — Agentic AI Safety & Multi-Agent Systems.
53:08 — Enterprise AI Mistakes & Where to Start.
01:08:26 — The Future of Agentic Commerce & One-Person Companies.
Follow Matt White: / mdwdata.
Follow Anthony Sar: / anthonysar.