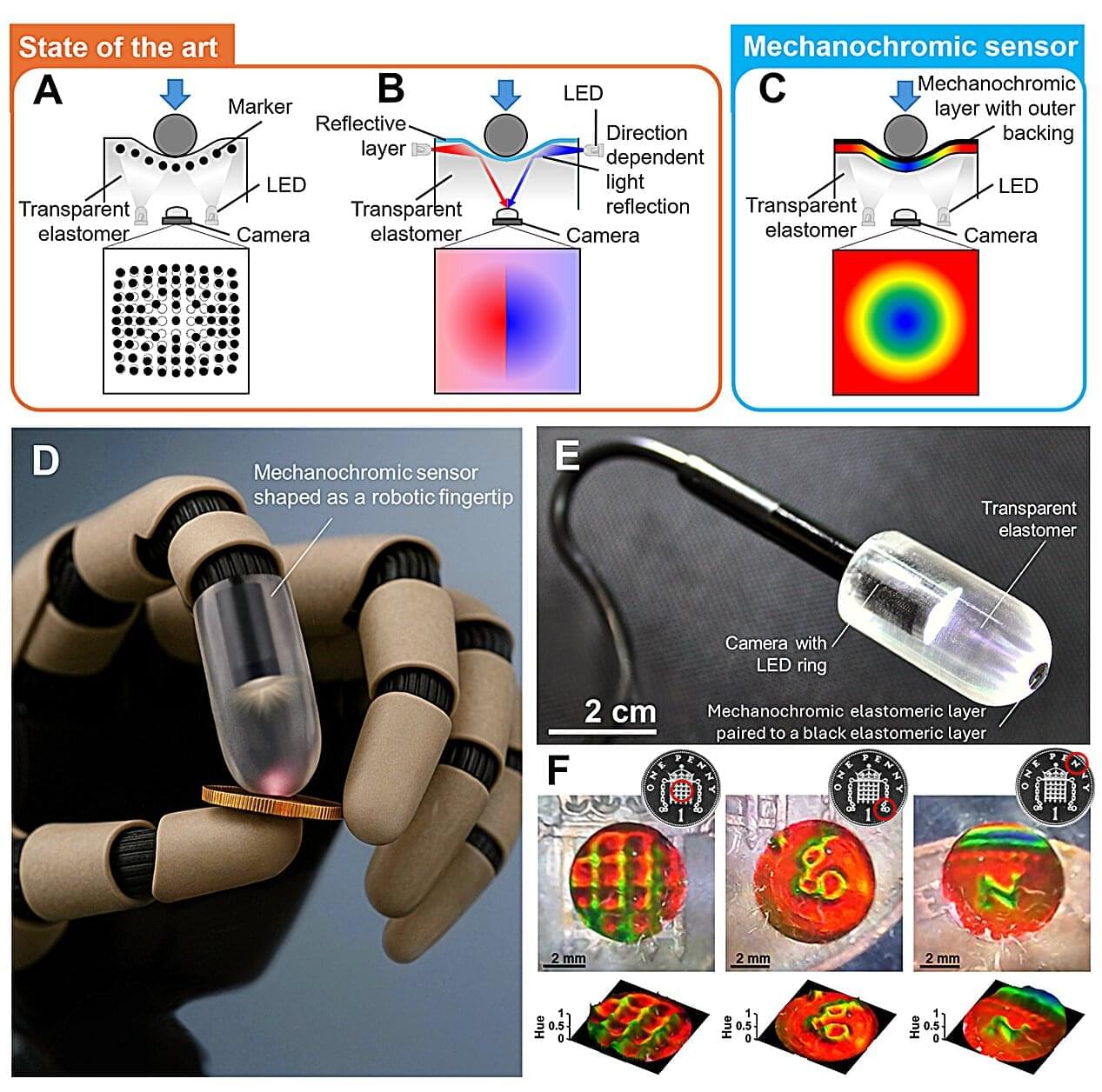
Engineers at Queen Mary University of London have built a new color-changing tactile sensor, which allows robots to “see” and touch in real-time. The novel idea was invented by Giacomo Sasso, a postdoctoral researcher at the School of Engineering and Materials Science at Queen Mary University of London, and it works by transforming invisible forces into dynamic color patterns. This enables high-resolution maps of contact, strain and pressure to emerge instantly.
The study is published in the journal Science Advances.
When pressure is applied to a soft sensing surface, the material produces spatially varying structural colors that can be captured immediately using a standard camera, removing the need for complex reconstruction algorithms.
Free field theory. free field. quantum field.theory. quantum field theory in a nutshell pdf. quantum field frequency. quantum field theory problems and solutions pdf. quantum field theory as simply as possible pdf. quantum field theory for beginners. quantum field theory books for beginners. quantum field theory from basics to modern topics. quantum field theory and critical phenomena pdf. quantum field theory and critical phenomena. quantum field theory problems and solutions. difference between quantum field theory and quantum mechanics. effective field theory mit. e field equation. effective field theory pdf. fields in quantum field theory. no-nonsense quantum field theory pdf. quantum field theory and general relativity. quantum field theory gravity. h field equation. free field hamiltonian. quantum field theory handwritten notes. the field quantum physics. introduction to quantum field theory pdf. quantum field theory pdf. quantum field theory for mathematicians pdf. m field theory. quantum field theory mit. no-nonsense quantum field theory a student-friendly introduction. physics field theory. philosophy of quantum field theory. problems with quantum field theory. quantum field theory vs quantum mechanics. relativistic quantum field theory pdf. relative quantum field theory. quantum field theory research. quantum field theory simple explanation. quantum field theory srednicki pdf. quantum field theory for undergraduates. unified field theory vs quantum mechanics. quantum field theory vs general relativity. quantum field theory weinberg pdf. quantum field theory experiments. zee quantum field theory in a nutshell pdf. quantum field theory zee pdf. quantum field theory zee. zee quantum field theory in a nutshell. field theory physics pdf. the quantum theory of fields volume 1 how many fields are there in quantum field theory. quantum field theory for dummies.
🌌 Holographic theory suggests a profound idea: the universe may store information on its boundary, while the spacetime we experience emerges from that information. In this view, gravity is not only a force between masses.
“Advances in quantum research and development have shifted the risk horizon,” Mark Russinovich, chief technology officer of Microsoft Azure, said. “We believe cryptographically relevant quantum computers could arrive sooner than previously expected – and the work required to prepare is significant, so organizations need to start now.”
To that end, the Windows maker is speeding up the Microsoft Quantum Safe Program (QSP) timeline with the goal of transitioning critical products and services to post-quantum cryptography (PQC) by 2029. The company is also planning to incorporate PQC requirements into its Secure Future Initiative (SFI).
Some key focus areas include upgrading network cryptography by adopting TLS 1.3, building crypto-agility for stored data to facilitate the ability to change cryptography without having to redesign the underlying systems, and transitioning to PQC algorithms to secure trust chains, such as code signing, certificate issuance, key protection, and update pipelines.
Confidential Computing (CC) safeguards data during processing, not just storage or transmission. It allows sensitive data, such as cryptographic keys, AI agent reasoning stages, and proprietary algorithms, to be computed safely without external access or modification. As AI systems become more independent and interconnected, confidential computing ensures computation integrity and privacy end-to-end.
The standard approach to satellite imagery is to snap huge batches of pictures and beam them back to Earth, where they can be sifted through by human operators and the best available algorithms.
It’s all worked well so far, but the time, transmission bandwidth, and energy required are starting to become bottlenecks. Modern satellites are simply capturing more pixels than scientists have time to look at.
However, the YAM-9 satellite has just done something different: It has identified and described features in its image scans without needing to check back with ground control.
This new approach can identify worse-case scenarios that an engineer might miss if they use a traditional method that compares an algorithm against a set of human-designed past test cases. It is also less labor-intensive than other verification tools that require engineers to rewrite an algorithm in a complex mathematical code each time they want to test it.
Instead of needing a mathematical reformulation, the new method reads the algorithm’s source code directly and automatically searches for worse-case scenarios that lead to the highest level of underperformance.
By helping engineers quickly and easily stress-test a networking algorithm before deployment, the method could catch failure modes that might otherwise only appear in a real outage. The technique could also be used to analyze the risks of deploying AI-generated code.
Microsoft announced today that it is accelerating its quantum-safe security roadmap, saying advances in quantum computing are bringing the need to replace today’s encryption standards sooner than previously expected.
Although today’s quantum computers cannot crack modern encryption, security researchers have warned about “harvest now, decrypt later” attacks. In these attacks, encrypted data that is stolen today is stored until future quantum computers become powerful enough to decrypt it, exposing sensitive information.
As a result, companies including Apple, Google, and Signal have begun integrating post-quantum cryptography (PQC) to replace existing public-key encryption algorithms with quantum-resistant versions.
To harness biological systems (plants and microbes) for next-generation energy production and advanced materials, researchers are looking to beneficial plant-microbe interactions. Because these are complex systems, it has proven difficult to reproducibly control exactly which microbes are present. And, subtle differences in materials, methods, or even the hands of the researchers themselves can lead to inconsistent results. This makes it difficult to replicate previous work, significantly slowing the leap from scientific discovery to practical application.
Researchers at Lawrence Berkeley National Laboratory (Berkeley Lab) are overcoming this bottleneck by addressing a multi-layered challenge: building reliable physical hardware, engineering accurate visual sensors, and developing predictive algorithms. Their solution, EcoBOT, stands out from typical plant phenotyping facilities by integrating these distinct components into a reliably automated workflow under strictly sterile conditions.
EcoBOT takes specialized growth chambers, called EcoFABs, and integrates them with machine-learning tools that autonomously guide the discovery cycle. This system uses advanced imaging to regularly scan the entire plant—from the tips of its leaves to the bottom of its roots. By using Gaussian Process models and AI analysis tools, it can quickly analyze and model this visual data to calculate the most informative next steps. This directs the automated hardware to determine exactly how plants adapt to environmental stressors, establishing the crucial microbe-free baseline needed to eventually study plant-microbe interactions and engineer better bioenergy crops.