Geophysicists at ETH Zurich are using models of the lower mantle to identify areas where earthquake waves behave differently than previously assumed. This indicates the presence of zones of rocks that are colder, or have a different composition, than the surrounding rocks. This finding challenges our current understanding of the Earth’s plate tectonics – and presents the researchers with a major mystery.
Chris Langan, 72, is an American horse rancher who is alleged to have an IQ between 190 and 210. That ‘genius’ score is 30 to 50 points higher than Albert Einstein’s.
Researchers unveil how biological sex influences brain aging, revealing genetic, hormonal, and molecular mechanisms behind cognitive resilience and decline.
At CES 2025, Elon Musk joined Mark Penn the Stagwell CEO, and 25 CMOs to discuss AI, robotics, Neuralink, space exploration, and Mars colonization. Musk shared bold predictions on AI’s role in cognitive tasks, humanoid robots, autonomous cars, and X’s future as a platform for collective human consciousness. They also explored government’s role in tech, internet connectivity, and combating global pessimism.
00:00 Introduction and Welcome. 01:52 Elon Musk on AI and Future Technology. 05:12 Advancements in Self-Driving Cars. 07:23 Humanoid Robots and Their Impact. 09:26 Mars Colonization Plans. 11:24 Neuralink and Brain-Computer Interfaces. 14:03 Government Efficiency and Budget Cuts. 17:49 Freedom of Speech and Social Media. 23:50 Optimism for the Future.
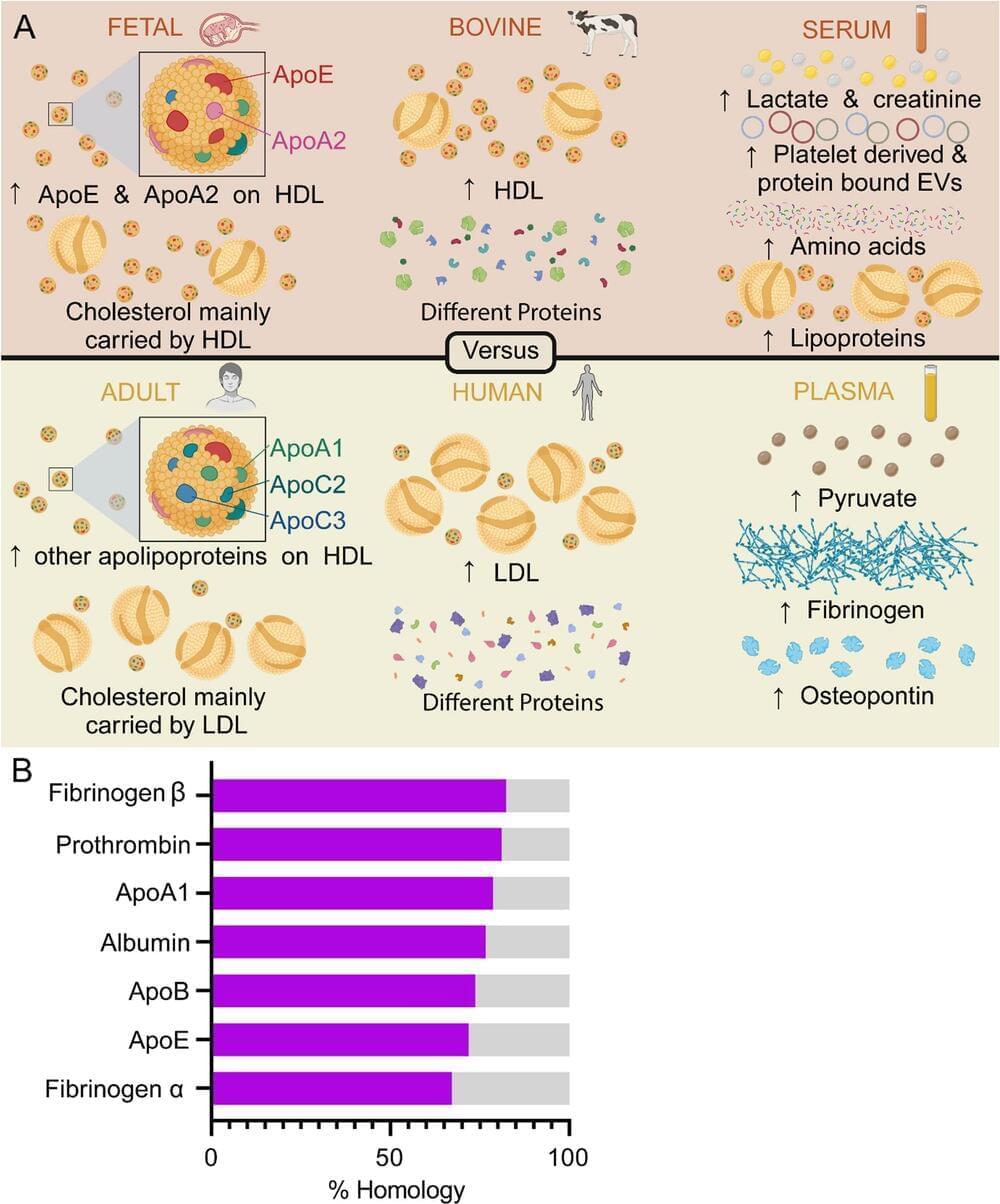
An informative review on the benefits and drawbacks and biological effects of various kinds of in vitro cell culture media.
The biomolecular relevance of medium supplements is a key challenge affecting cell culture practice. The biomolecular composition of commonly used supplements differs from that of a physiological environment, affecting the validity of conclusions drawn from in vitro studies. This article discusses the advantages and disadvantages of common supplements, including context-dependent considerations for supplement selection to improve biomolecular relevance, especially in nanomedicine and extracellular vesicle research.
Back in 2021, a test of cephalopod smarts reinforced how important it is for us humans to not underestimate animal intelligence.
Cuttlefish were given a new version of the marshmallow test, and the results may demonstrate that there’s more going on in their strange little brains than we knew.
Their ability to learn and adapt, the researchers said, could have evolved to give cuttlefish an edge in the cutthroat eat-or-be-eaten marine world they live in.