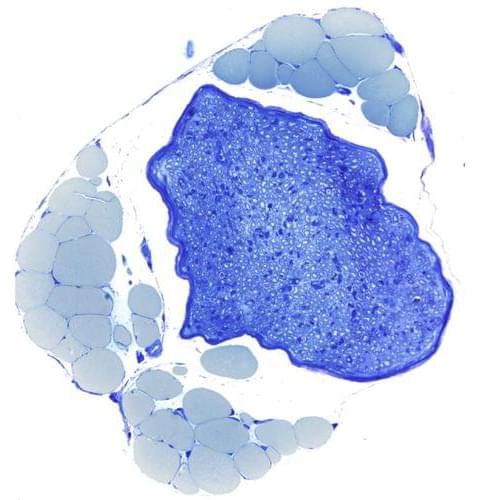
Damage to the body’s peripheral nerves can cause pain and movement disorders. Researchers at Leipzig University have recently investigated how damaged nerves can regenerate better. They found that fat tissue strongly supports the Schwann cells needed for repair during the healing process. The results were published in the renowned journal “Cell Metabolism”
Our bodies are transversed by millions of nerve fibres that transmit information. This allows us to do things like control muscles and perceive sensory impressions. Peripheral nerves, like those in our arms and legs, are often damaged by acute injuries, for example, in accidents. As a result, those affected suffer from loss of muscle strength and sensory problems such as numbness. Peripheral nerves do have a strong regenerative potential, but complete recovery of nerve function is still rare for reasons that are not yet fully understood.
When a nerve is crushed or severed, the individual nerve fibres affected by the damage initially die. In principle, they have the ability to grow back and regenerate completely. This depends on the Schwann cells that surround the nerve fibres. These cells do not die after nerve damage, but instead are responsible for coordinating the breakdown and regrowth of nerve fibres in their original areas. Schwann cells therefore play a key role in the repair process. It was previously unknown how these cells cope with the enormous metabolic load associated with the breakdown and rebuilding of nerve tissue. Researchers at the University of Leipzig Medical Center have now discovered that Schwann cells receive crucial support with nerve repair from the fat tissue that surrounds nerves in the body. Using genetically modified mice, they have shown that the chemical messenger leptin plays a key role in this process.