Diffusion models have recently produced outstanding results on various generating tasks, including the creation of images, 3D point clouds, and molecular conformers. Ito stochastic differential equations (SDE) are a unified framework that can incorporate these models. The models acquire knowledge of time-dependent score fields through score-matching, which later directs the reverse SDE during generative sampling. Variance-exploding (VE) and variance-preserving (VP) SDE are common diffusion models. EDM offers the finest performance to date by expanding on these compositions. The existing training method for diffusion models can still be enhanced, despite achieving outstanding empirical results.
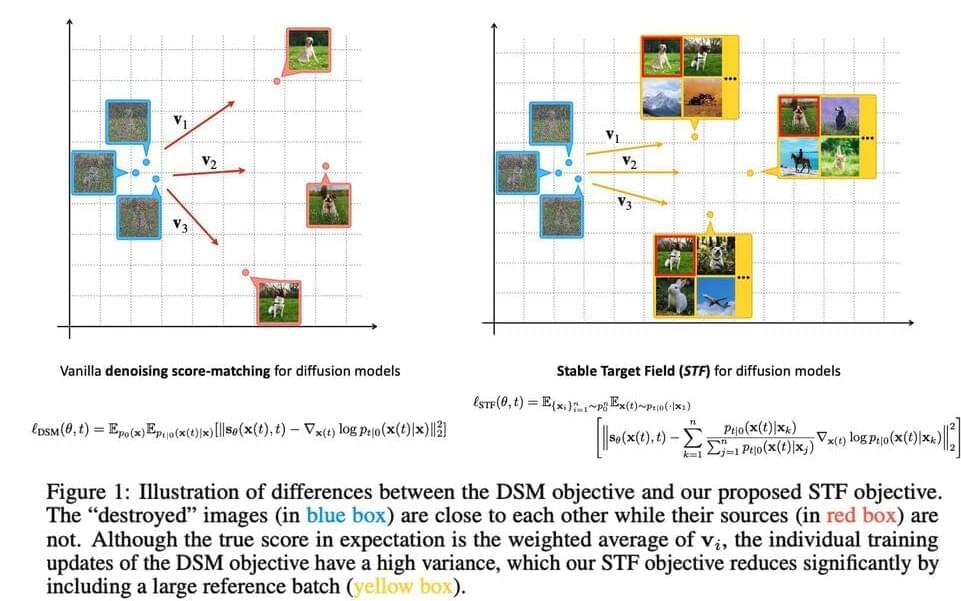
The Stable Target Field (STF) objective is a generalized variation of the denoising score-matching objective. Particularly, the high volatility of the denoising score matching (DSM) objective’s training targets can result in subpar performance. They divide the score field into three regimes to comprehend the cause of this volatility better. According to their investigation, the phenomenon mostly occurs in the intermediate regime, defined by various modes or data points having a similar impact on the scores. In other words, under this regime, it is still being determined where the noisy samples produced throughout the forward process originated. Figure 1(a) illustrates the differences between the DSM and their proposed STF objectives.
Figure 1: Examples of the DSM objective’s and our suggested STF objective’s contrasts.






{kind=link}