Computer vision, one of the major areas of artificial intelligence, focuses on enabling machines to interpret and understand visual data. This field encompasses image recognition, object detection, and scene understanding. Researchers continuously strive to improve the accuracy and efficiency of neural networks to tackle these complex tasks effectively. Advanced architectures, particularly Convolutional Neural Networks (CNNs), play a crucial role in these advancements, enabling the processing of high-dimensional image data.
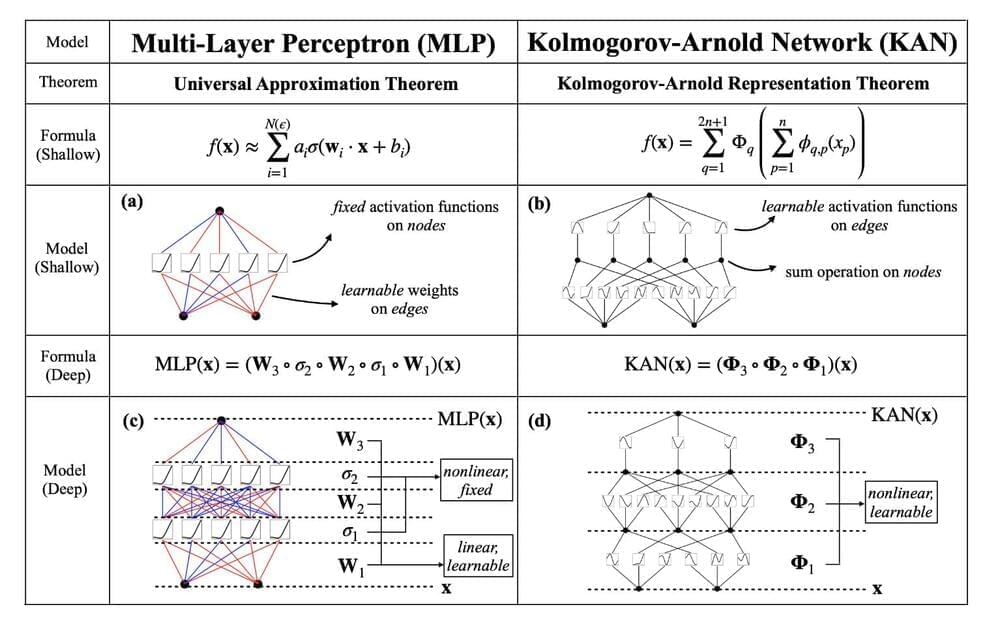
One major challenge in computer vision is the substantial computational resources required by traditional CNNs. These networks often rely on linear transformations and fixed activation functions to process visual data. While effective, this approach demands many parameters, leading to high computational costs and limiting scalability. Consequently, there’s a need for more efficient architectures that maintain high performance while reducing computational overhead.
Current methods in computer vision typically use CNNs, which have been successful due to their ability to capture spatial hierarchies in images. These networks apply linear transformations followed by non-linear activation functions, which help learn complex patterns. However, the significant parameter count in CNNs poses challenges, especially in resource-constrained environments. Researchers aim to find innovative solutions to optimize these networks, making them more efficient without compromising accuracy.