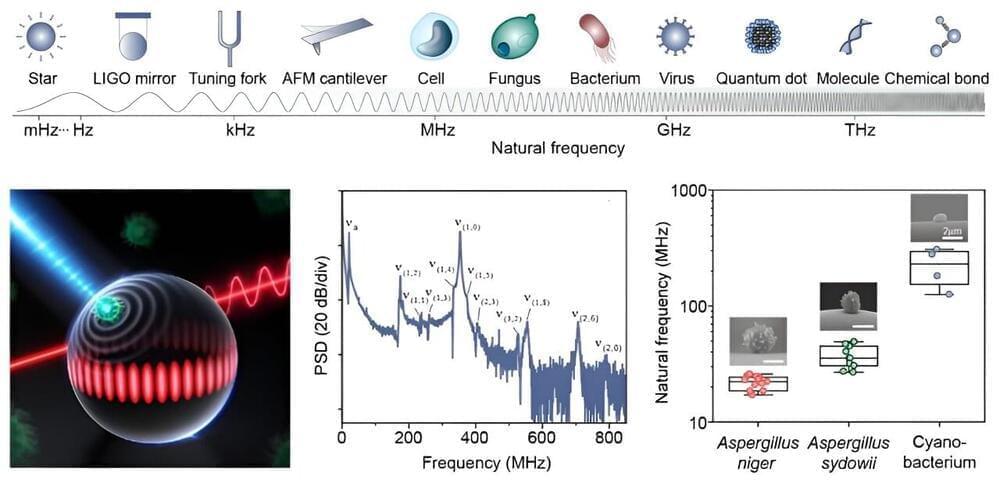
Pythagoras first discovered that the vibrations of strings are drastically enhanced at certain frequencies. This discovery forms the basis of our tone system. Such natural vibrations ubiquitously exist in objects regardless of their size scales and are widely utilized to derive their species, constituents, and morphology. For example, molecular vibrations at a terahertz rate have become the most common fingerprints for the identification of chemicals and the structural analysis of large biomolecules.
Recently, natural vibrations of particles at the mesoscopic scale have received growing interest, since this category includes a wide range of functional particles, as well as most biological cells and viruses. However, natural vibrations of these mesoscopic particles have remained hidden from existing technologies.
These particles with sizes ranging from 100 nm to 100 μm are expected to vibrate faintly at megahertz to gigahertz rates. This frequency regime could not be resolved by current Raman and Brillouin spectroscopies, however, due to strong Rayleigh-wing scattering, while the performances of piezoelectric techniques that are widely exploited in macroscopic systems degrade significantly at frequencies beyond a few megahertz.