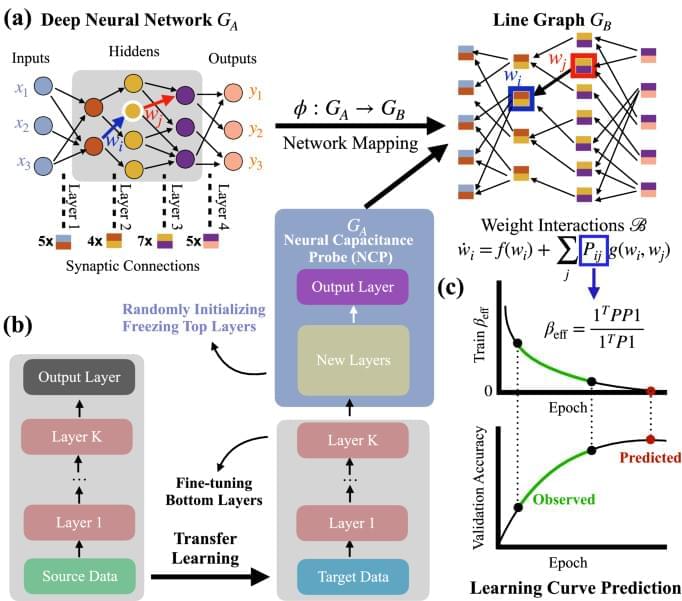
Machine learning influences numerous aspects of modern society, empowers new technologies, from Alphago to ChatGPT, and increasingly materializes in consumer products such as smartphones and self-driving cars. Despite the vital role and broad applications of artificial neural networks, we lack systematic approaches, such as network science, to understand their underlying mechanism. The difficulty is rooted in many possible model configurations, each with different hyper-parameters and weighted architectures determined by noisy data. We bridge the gap by developing a mathematical framework that maps the neural network’s performance to the network characters of the line graph governed by the edge dynamics of stochastic gradient descent differential equations. This framework enables us to derive a neural capacitance metric to universally capture a model’s generalization capability on a downstream task and predict model performance using only early training results. The numerical results on 17 pre-trained ImageNet models across five benchmark datasets and one NAS benchmark indicate that our neural capacitance metric is a powerful indicator for model selection based only on early training results and is more efficient than state-of-the-art methods.









Leave a reply