The advent of large language models (LLMs) like GPT-4 has sparked excitement around enhancing them with multimodal capabilities to understand visual data alongside text. However, previous efforts to create powerful multimodal LLMs have faced challenges in scaling up efficiently while maintaining performance. To mitigate these issues, the researchers took inspiration from the mixture-of-experts (MoE) architecture, widely used to scale up LLMs by replacing dense layers with sparse expert modules.
In the MoE approach, instead of passing inputs through a single large model, there are many smaller expert sub-models that each specialize on a subset of the data. A routing network determines which expert(s) should process each input example. It allows scaling up total model capacity in a more parameter-efficient way.
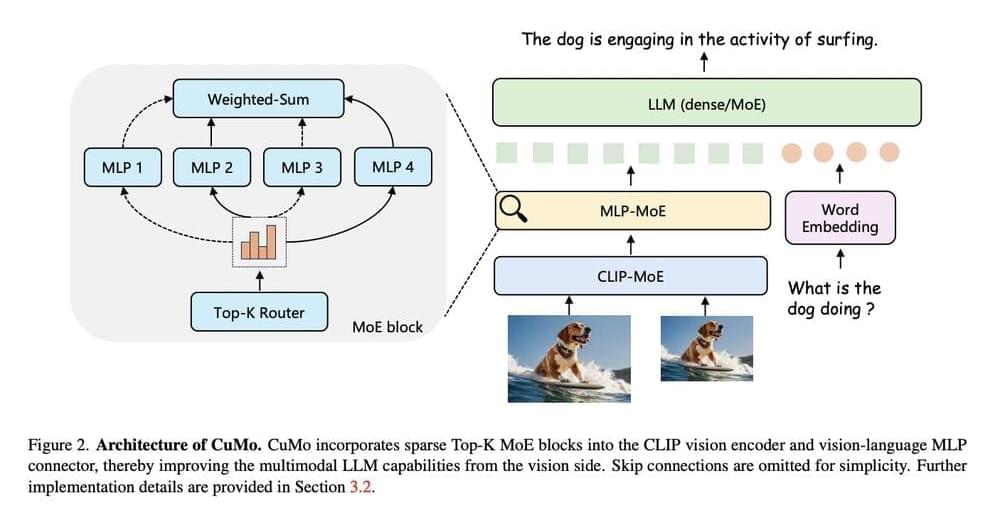
In their approach (shown in Figure 2), CuMo, the researchers integrated sparse MoE blocks into the vision encoder and the vision-language connector of a multimodal LLM. This allows different expert modules to process different parts of the visual and text inputs in parallel rather than relying on a monolithic model to analyze everything.









Leave a reply