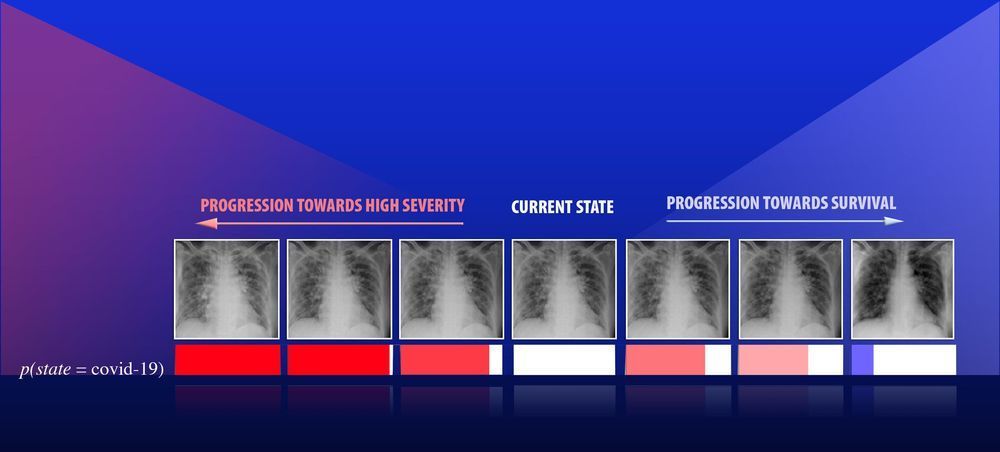
As artificial intelligence (AI) becomes increasingly used for critical applications such as diagnosing and treating diseases, predictions and results regarding medical care that practitioners and patients can trust will require more reliable deep learning models.
In a recent preprint (available through Cornell University’s open access website arXiv), a team led by a Lawrence Livermore National Laboratory (LLNL) computer scientist proposes a novel deep learning approach aimed at improving the reliability of classifier models designed for predicting disease types from diagnostic images, with an additional goal of enabling interpretability by a medical expert without sacrificing accuracy. The approach uses a concept called confidence calibration, which systematically adjusts the model’s predictions to match the human expert’s expectations in the real world.
“Reliability is an important yardstick as AI becomes more commonly used in high-risk applications, where there are real adverse consequences when something goes wrong,” explained lead author and LLNL computational scientist Jay Thiagarajan. “You need a systematic indication of how reliable the model can be in the real setting it will be applied in. If something as simple as changing the diversity of the population can break your system, you need to know that, rather than deploy it and then find out.”








Comments are closed.